Neste artigo, vamos explorar como configurar um servidor de IA local usando Ollama e o modelo Llama 3.1. Utilizaremos uma rede local onde um computador com uma placa gráfica Nvidia servirá como o servidor de IA. Outros computadores na rede utilizarão AnythingLLM para criar um assistente virtual capaz de aprender com documentos, escanear websites e salvar o conhecimento adquirido em disco para uso futuro. Além disso, usaremos o serviço ngrok para tornar nosso modelo acessível online, fora da nossa rede local.
Preparação do Ambiente
Requisitos de Hardware e Software
Computador Servidor: Um computador com uma GPU Nvidia que será usado para executar o modelo de IA.
Sistema Operacional: Embora uma distribuição Linux seja recomendada, este tutorial é totalmente aplicável no Windows. Em um vídeo que acompanharemos, mostraremos o passo a passo utilizando o Windows para demonstrar que qualquer usuário pode criar um servidor de IA, independentemente do sistema operacional.
Plataforma de IA: Ollama para gerenciar e servir o modelo Llama 3.1.
Rede Local: Os computadores clientes e o servidor devem estar conectados à mesma rede local.
Ollama é uma plataforma flexível que facilita a execução e gestão de grandes modelos de linguagem. O processo de instalação do Ollama é simples e suporta múltiplos sistemas operacionais, incluindo macOS, Windows e Linux, bem como ambientes Docker, garantindo ampla usabilidade e flexibilidade. Para instalar:
Baixe e Instale o Docker (se ainda não estiver instalado):
No Windows, você pode instalar o Docker Desktop diretamente.
Extraia o arquivo baixado e mova o executável para um local de sua preferência.
Autentique o ngrok:
Abra o Prompt de Comando ou PowerShell e navegue até o diretório onde o ngrok está localizado.
Adicione seu token de autenticação (disponível no painel do ngrok) com o comando:
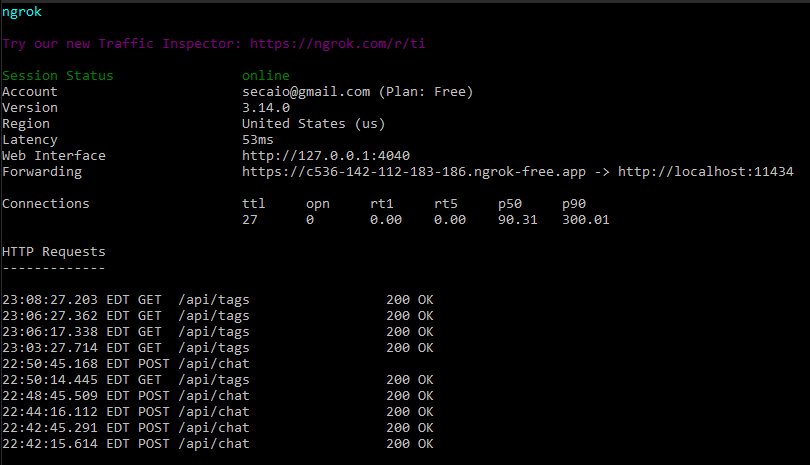
Inicie o ngrok:
Para criar um tunnel para o seu servidor Ollama, execute o commando:
Isso criará um túnel HTTP para a porta 11434 (ou a porta onde seu servidor Ollama está rodando).
Acesse o Servidor Ollama Online:
O ngrok fornecerá um URL público que você pode usar para acessar seu servidor Ollama.
A URL será algo como: https://c536-142-112-183-186.ngrok-free.app.
Use esse URL no seu navegador ou em comandos HTTP para acessar o servidor Ollama remotamente.
Configurando AnythingLLM nos Computadores Clientes
AnythingLLM é uma ferramenta poderosa para criar assistentes virtuais personalizados.
Instalando o AnythingLLM
Pré-requisitos:
Certifique-se de que o Python 3.8 ou superior esteja instalado.
Instale os pacotes necessários:
Configuração do Cliente:
Configure o AnythingLLM para se conectar ao servidor Ollama:
Criando e Treinando o Assistente Virtual
Adicionando Documentos:à
Carregue documentos locais para treinar o assistente:
Escaneando Websites:
Configure o assistente para escanear e aprender com websites:
Salvando Conhecimento:
Todo o conhecimento adquirido é salvo em disco para uso futuro:
Utilizando o Assistente Virtual
Uma vez configurado, o assistente virtual estará pronto para ser utilizado em qualquer computador da rede. Ele pode responder a consultas, realizar buscas em documentos e fornecer informações baseadas no conhecimento adquirido.
Interagindo com o Assistente:
Use a interface CLI interagir com o assistente:
Use a Interface Gráfica do AnyThingLLM ou crie uma interface gráfica simples para interagir com o assistente:
Conclusão
Neste guia, percorremos o processo de instalação e uso do Ollama no Windows, destacando sua configuração simples e poderosas capacidades. Seguindo os passos fornecidos, você pode facilmente implantar e gerenciar grandes modelos de linguagem localmente, aproveitando a aceleração da GPU e garantindo que seus dados permaneçam privados.
Criar um servidor de IA local usando Ollama e Llama 3.1 é uma solução eficiente para aqueles que buscam total controle sobre seus modelos de linguagem e desejam integrá-los a uma rede local. Com a adição do AnythingLLM, você pode facilmente criar um assistente virtual personalizado que aprende continuamente, escaneia sites e armazena conhecimento para uso futuro.