This article will explore how to set up a local AI server using Ollama and the Llama 3.1 model. We will use a local network where one computer with an Nvidia graphics card will serve as the AI server. Other computers on the network will use AnythingLLM to create a virtual assistant capable of learning from documents, scanning websites, and saving the acquired knowledge to disk for future use. Additionally, we will use the ngrok service to make our model accessible online, outside of our local area network.
The Environment
Hardware and Software Requirements
Server Computer: A computer with an Nvidia GPU that will be used to run the AI model.
Operating System: Although a Linux distribution is recommended, this tutorial is fully applicable on Windows. In an accompanying video, we will demonstrate the steps using Windows to show that anyone can set up an AI server regardless of the operating system.
AI Platform: Ollama to manage and serve the Llama 3.1 model.
Local Network: The client computers and the server must be connected to the same local network.
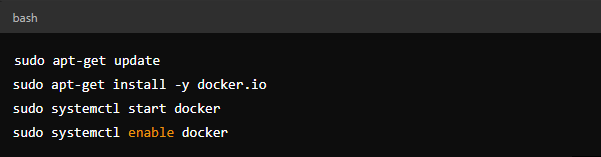
Ollama is a flexible platform that facilitates the execution and management of large language models. The installation process for Ollama is straightforward and supports multiple operating systems including macOS, Windows, and Linux, as well as Docker environments, ensuring broad usability and flexibility. To install:
Download and Install Docker (if not already installed):
On Windows, you can install Docker Desktop directly.
Extract the downloaded file and move the executable to a preferred location.
Authenticate ngrok:
Open Command Prompt or PowerShell and navigate to the directory where ngrok is located.
Add your authentication token (available in the ngrok dashboard) with the command:
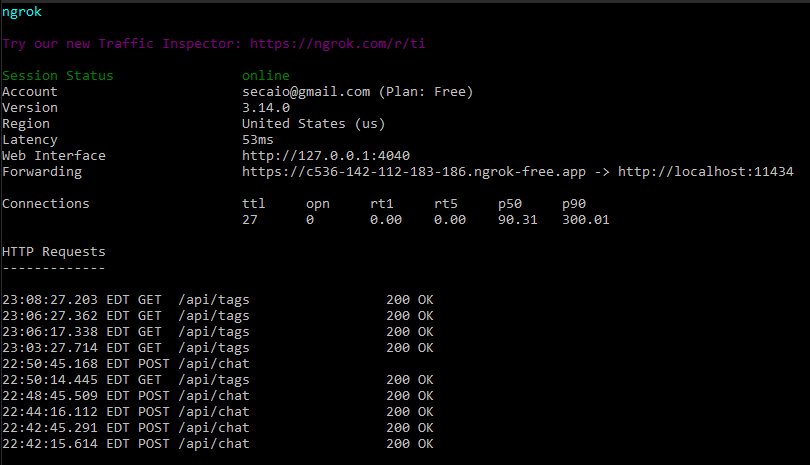
Start ngrok:
To create a tunnel to your Ollama server, run the command:
This will create an HTTP tunnel to port 11434 (or the port where your Ollama server is running).
Access the Ollama Server Online:
ngrok will provide a public URL that you can use to access your Ollama server.
The URL will be something like: https://c536-142-112-183-186.ngrok-free.app.
Use this URL in your browser or HTTP commands to access the Ollama server remotely.
Setting Up AnythingLLM on Client Computers
AnythingLLM is a powerful tool for creating personalized virtual assistants.
Installing AnythingLLM
Prerequisites:
Ensure that Python 3.8 or higher is installed.
Install the necessary packages:
Client Configuration:
Configure AnythingLLM to connect to the Ollama server:
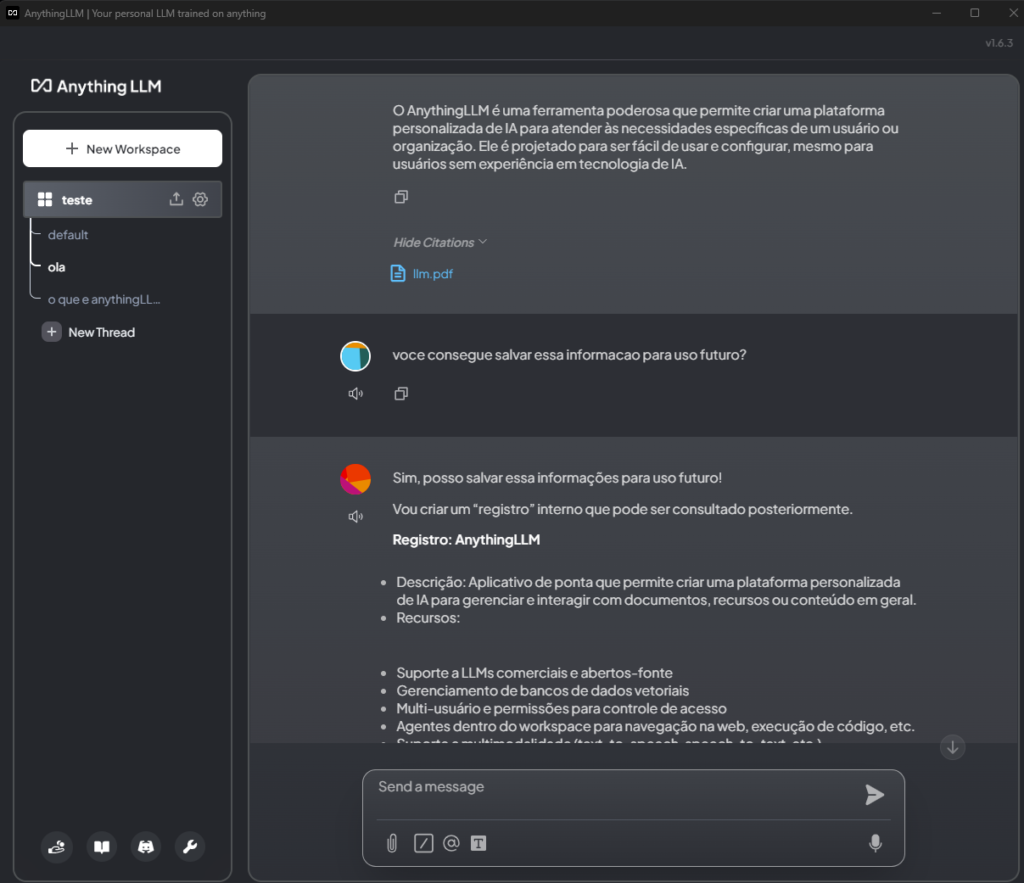
Creating and Training the Virtual Assistant
Adding Documents:
Upload local documents to train the assistant:
Scanning Websites:
Set up the assistant to scan and learn from websites:
Saving Knowledge:
All acquired knowledge is saved to disk for future use:
Using the Virtual Assistant
Once configured, the virtual assistant will be ready to use on any computer within the network. It can respond to queries, search documents, and provide information based on the knowledge it has acquired.
Interacting with the Assistant:
Use a simple GUI to interact with the assistant:
Use the CLI interface of AnyThingLLM or create a GUI yourself to interact with the assistant:
Conclusion
In this guide, we walked through the process of installing and using Ollama on Windows, highlighting its straightforward setup and powerful capabilities. By following the steps provided, you can easily deploy and manage large language models locally, benefiting from GPU acceleration and ensuring your data remains private.
Creating a local AI server using Ollama and Llama 3.1 is an efficient solution for those seeking full control over their language models and wanting to integrate them into a local network. With the addition of AnythingLLM, you can easily create a personalized virtual assistant that continuously learns, scans websites, and stores knowledge for future use.
While Ollama provides a flexible and private way to leverage the power of AI on your own hardware, Llama 3.1 represents a significant leap forward in the field of natural language processing, offering unprecedented opportunities for developers and researchers to explore the potential of AI. AnythingLLM, on the other hand, empowers final users to harness the potential of AI through a convenient and accessible platform.